양날의 검!
@Transactional 어노테이션은 개발에서 자주 사용됩니다. 이 어노테이션은 메소드 내에서 여러 개의 데이터베이스 작업이 모두 성공하거나 모두 실패하도록 보장합니다. @Transactional 어노테이션을 사용할 때는 많은 세부 사항을 고려해야하며, 그렇지 않으면 @Transactional이 항상 이상하게 실패한다는 것을 발견할 수 있습니다.
트랜잭션 개념만 살짝 언급, 깊게는 나도 몰랑!
트랜잭션 관리는 시스템 개발에서 불가결한 부분이며, Spring은 훌륭한 트랜잭션 관리 메커니즘을 제공합니다. 주로 프로그래밍 방식과 선언적 트랜잭션으로 구분됩니다.
프로그래밍 방식 트랜잭션: 코드에서 수동으로 커밋, 롤백 등 트랜잭션 조작을 하는 것을 말합니다. 코드 침입성이 상대적으로 강합니다. 아래는 예시입니다.
어떤 방식으로 제공되는가?
시스템 개발에서는 트랜잭션 관리가 필수적이며, Spring은 우수한 트랜잭션 관리 메커니즘을 제공합니다. 이 메커니즘은 프로그래밍 방식 트랜잭션과 선언적 트랜잭션 두 가지로 나뉩니다.
프로그래밍 방식
프로그래밍 방식 트랜잭션은 코드에서 수동으로 트랜잭션을 관리하는 것으로, 커밋, 롤백 등의 작업을 직접 처리합니다. 코드에 침투성이 높아지기 때문에 잘못 사용하면 문제가 발생할 수 있습니다. 다음은 예시입니다.
try {
//TODO something
transactionManager.commit(status);
} catch (Exception e) {
transactionManager.rollback(status);
throw new InvoiceApplyException("트랜잭션 처리 실패");
}선언적 방식
선언적 트랜잭션은 AOP(Aspect-Oriented Programming) 기반으로 구현되어 비즈니스 로직과 트랜잭션 처리 부분을 분리하여 코드 침투성을 낮춥니다. 실제로 개발에서는 선언적 트랜잭션을 주로 사용합니다. 선언적 트랜잭션은 두 가지 방법으로 구현할 수 있습니다. 하나는 TX와 AOP를 사용하는 XML 설정 파일 방식이고, 다른 하나는 @Transactional 어노테이션을 사용하는 방식입니다. 예시는 다음과 같습니다.
@Transactional
@GetMapping("/test")
public String test() {
int insert = cityInfoDictMapper.insert(cityInfoDict);
}@Transactional 소개
@Transactional 어노테이션은 어디에 적용될 수 있나요? @Transactional 어노테이션은 인터페이스, 클래스, 클래스 메소드에 적용될 수 있습니다.
- 클래스에 적용: @Transactional 어노테이션을 클래스에 적용하면, 클래스의 모든 public 메소드에 동일한 트랜잭션 속성 정보가 적용됩니다.
- 메소드에 적용: 클래스가 @Transactional 어노테이션을 가지고 있고, 메소드도 @Transactional 어노테이션을 가지고 있다면, 메소드의 트랜잭션 정보가 클래스의 트랜잭션 정보보다 우선합니다.
- 인터페이스에 적용: 이 방법은 권장되지 않습니다. 인터페이스에 @Transactional 어노테이션을 적용하고, Spring AOP가 CGLib 동적 프록시를 사용하는 경우 @Transactional 어노테이션을 잘못 처리할 수 있습니다.
@Transactional
@RestController
@RequestMapping
public class MybatisPlusController {
@Autowired
private CityInfoDictMapper cityInfoDictMapper;
@Transactional(rollbackFor = Exception.class)
@GetMapping("/test")
public String test() throws Exception {
CityInfoDict cityInfoDict = new CityInfoDict();
cityInfoDict.setParentCityId(2);
cityInfoDict.setCityName("2");
cityInfoDict.setCityLevel("2");
cityInfoDict.setCityCode("2");
int insert = cityInfoDictMapper.insert(cityInfoDict);
return insert + "";
}
}@Transactional 어노테이션 속성들…
propagation 속성: 트랜잭션 전파 동작을 나타냅니다. 기본값은 Propagation.REQUIRED입니다. 다른 속성 정보는 다음과 같습니다:
- Propagation.REQUIRED: 현재 트랜잭션이 있으면 해당 트랜잭션에 참여하고, 없으면 새로운 트랜잭션을 생성합니다. (기본적으로 A 메서드와 B 메서드 두 개의 메서드에 주석이 추가되어 있으며, 기본 전파 모드에서 A 메서드 내에서 B 메서드를 호출하면 두 개의 메서드의 트랜잭션이 하나의 트랜잭션으로 병합됩니다.)
- Propagation.SUPPORTS: 현재 트랜잭션이 존재하면 해당 트랜잭션에 참여하고, 없으면 트랜잭션 없이 계속 진행합니다.
- Propagation.MANDATORY: 현재 트랜잭션이 있으면 해당 트랜잭션에 참여하고, 없으면 예외를 발생시킵니다.
- Propagation.REQUIRES_NEW: 새로운 트랜잭션을 생성하고, 현재 트랜잭션이 존재하면 해당 트랜잭션을 일시 중단합니다. (A 클래스의 a 메서드가 기본 Propagation.REQUIRED 모드를 사용하고, B 클래스의 b 메서드가 Propagation.REQUIRES_NEW 모드를 사용하며, a 메서드에서 데이터베이스 작업을 수행하는 동안 예외가 발생하면, Propagation.REQUIRES_NEW는 a 메서드의 트랜잭션을 일시 중단하므로 b 메서드는 롤백되지 않습니다.)
- Propagation.NOT_SUPPORTED: 트랜잭션이 없는 상태에서 진행하며, 현재 트랜잭션이 존재하면 해당 트랜잭션을 일시 중단합니다.
- Propagation.NEVER: 트랜잭션이 없는 상태에서 진행하며, 현재 트랜잭션이 존재하면 예외를 발생시킵니다.
- Propagation.NESTED: Propagation.REQUIRED와 동일한 효과가 있습니다.
isolation 속성: 트랜잭션 격리 수준을 지정합니다. 기본값은 Isolation.DEFAULT입니다.
- Isolation.DEFAULT: 기본 데이터베이스 격리 수준을 사용합니다.
- Isolation.READ_UNCOMMITTED
- Isolation.READ_COMMITTED
- Isolation.REPEATABLE_READ
- Isolation.SERIALIZABLE
timeout 속성: 트랜잭션 제한 시간을 지정합니다. 기본값은 -1이며, 이는 시간 제한이 없음을 의미합니다. 만약 제한 시간을 초과하더라도 트랜잭션이 완료되지 않은 경우 자동으로 롤백됩니다.
readOnly 속성: 트랜잭션이 읽기 전용인지 여부를 지정합니다. 기본값은 false이며, 이는 트랜잭션이 읽기/쓰기 모두 가능함을 의미합니다. 읽기 작업만 수행하는 메소드와 같이 트랜잭션이 필요하지 않은 경우, readOnly를 true로 설정하여 성능을 개선할 수 있습니다.
rollbackFor 속성: 트랜잭션에서 롤백이 필요한 예외 타입을 지정합니다. 여러 예외 타입을 지정할 수 있습니다.
noRollbackFor 속성: 특정 예외 타입이 발생해도 롤백하지 않도록 지정할 수 있습니다. 여러 예외 타입을 지정할 수 있습니다.
@Transactional 어노테이션이 적용 안되는 케이스!
@Transactional이 public으로 선언되지 않은 메서드에 적용되는 경우- @Transactional이 public으로 선언되지 않은 메서드에 적용된 경우
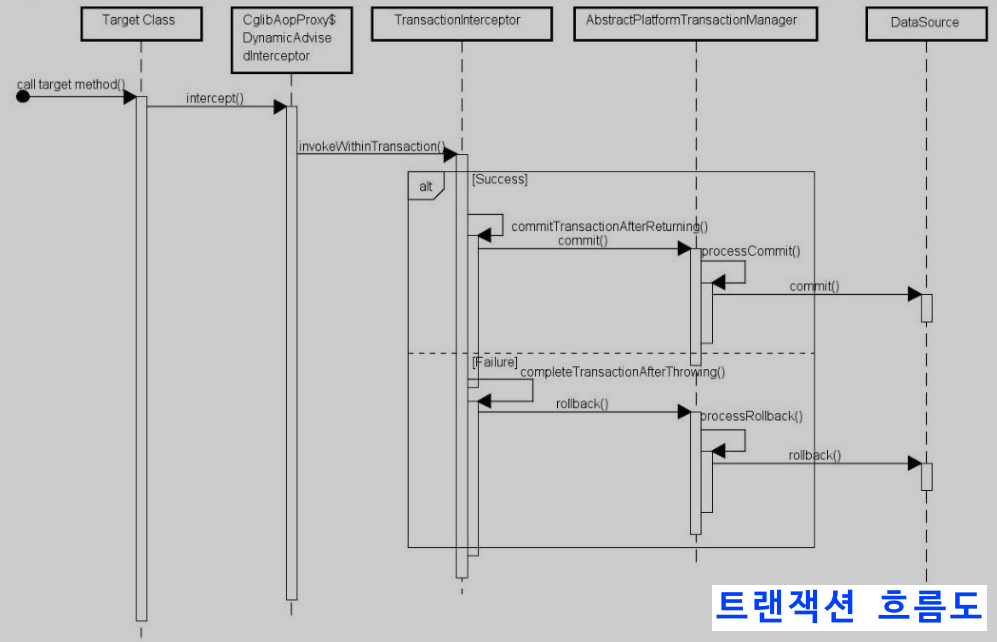
@Transactional이 public이 아닌 메소드에 적용되었을 경우에는 @Transactional이 작동하지 않는다. 이는 Spring AOP 프록시에서 발생하는데, TransactionInterceptor(트랜잭션 인터셉터)는 대상 메소드 실행 전후에 가로채며, DynamicAdvisedInterceptor(CglibAopProxy의 내부 클래스)의 intercept 메소드 또는 JdkDynamicAopProxy의 invoke 메소드는 간접적으로 AbstractFallbackTransactionAttributeSource의 computeTransactionAttribute 메소드를 호출하여 @Transactional의 트랜잭션 구성 정보를 가져옵니다.
protected TransactionAttribute computeTransactionAttribute(Method method, Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}computeTransactionAttribute 메소드는 대상 메소드의 수정자(modifier)가 public인지 여부를 확인하고, public이 아니라면 @Transactional 속성 구성 정보를 가져오지 않습니다.
주의: protected, private로 선언된 메서드에 @Transactional 어노테이션을 사용하더라도, 트랜잭션이 적용되지 않을 뿐만 아니라 오류 메시지도 나타나지 않으므로, 이 점에 대해서 주의해야 합니다.- @Transactional 어노테이션의 propagation 속성 설정 오류
이러한 실패는 구성 오류로 인해 발생하며, 아래 세 가지 propagation을 잘못 구성하면 트랜잭션이 롤백되지 않습니다.
- TransactionDefinition.PROPAGATION_SUPPORTS: 현재 트랜잭션이 있는 경우 해당 트랜잭션에 참여하고, 트랜잭션이 없는 경우 트랜잭션 없이 계속 실행됩니다.
- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 트랜잭션 없이 실행되며, 현재 트랜잭션이 있는 경우 현재 트랜잭션을 일시 중지합니다.
- TransactionDefinition.PROPAGATION_NEVER: 트랜잭션이 없이 실행되며, 현재 트랜잭션이 있는 경우 예외가 발생합니다.
- @Transactional 어노테이션의 rollbackFor 속성 설정 오류
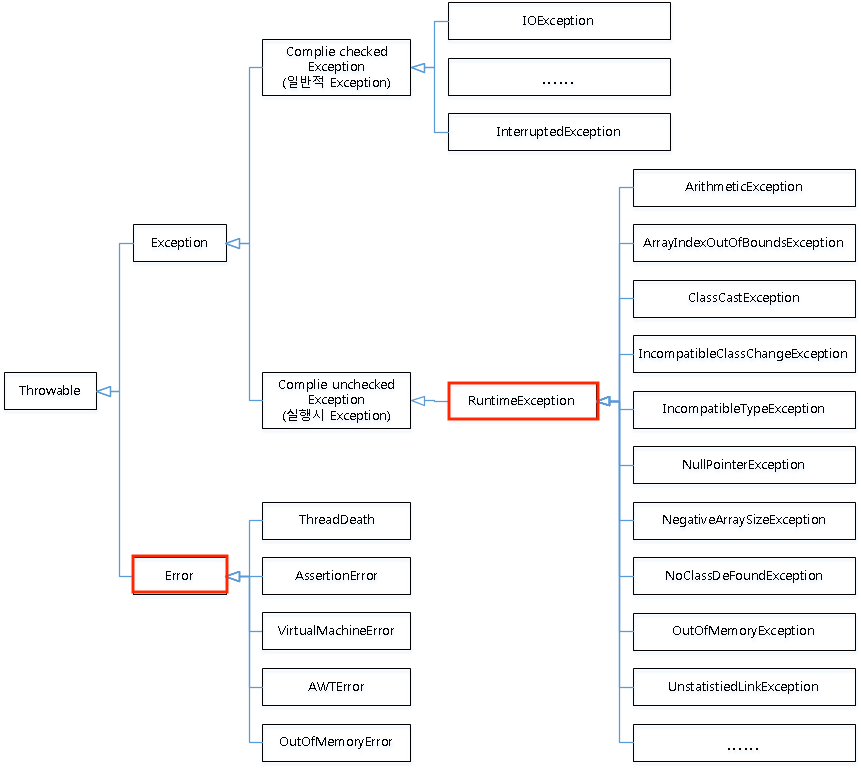
rollbackFor 속성을 사용하여 트랜잭션 롤백을 유발시킬 수 있는 예외 유형을 지정할 수 있습니다. Spring은 기본적으로 확인되지 않은 unchecked 예외 (RuntimeException에서 상속된 예외) 또는 오류(Error)만 롤백합니다. 다른 예외는 트랜잭션 롤백을 유발시키지 않습니다. 따라서 다른 유형의 예외가 트랜잭션에서 발생하더라도 Spring이 트랜잭션 롤백을 유발시키기를 원하는 경우 rollbackFor 속성을 지정해야합니다.
//MyException이 발생하면 트랜잭션을 롤백하도록 설정하고 싶을 때 사용하는 예시 코드입니다.
@Transactional(propagation= Propagation.REQUIRED,rollbackFor= MyException.class재귀적으로 Throwable 클래스의 하위 클래스들을 탐색하면서 주어진 예외 클래스 이름을 찾는 메서드입니다.
private int getDepth(Class<?> exceptionClass, int depth) {
// 만약 현재 클래스가 주어진 예외 클래스 이름을 포함하고 있다면 찾았다!
if (exceptionClass.getName().contains(this.exceptionName)) {
return depth;
}
// 만약 Throwable 클래스까지 갔는데도 찾지 못했다면 -1을 반환한다.
if (exceptionClass == Throwable.class) {
return -1;
}
// 현재 클래스의 슈퍼클래스로 재귀 호출한다.
return getDepth(exceptionClass.getSuperclass(), depth + 1);
}위 문장은 Spring Framework에서 @Transactional어노테이션에 rollbackFor속성이 지정된 경우, 해당 속성값으로 지정된 예외 클래스의 하위 클래스가 발생한 경우에도 트랜잭션이 롤백된다는 것을 설명하고 있습니다. 아래는 Spring Framework 소스 코드의 일부분입니다.
public void commit(TransactionStatus status) throws TransactionException {
try {
// 커밋 전에 트랜잭션 롤백 가능성을 체크한다.
if (status.isRollbackOnly()) {
if (status.isNewTransaction()) {
// 롤백-전파 속성이 MANDATORY일 경우, 예외를 던진다.
throw new IllegalTransactionStateException(
"Transaction marked as rollback-only but committed instead of rolling back");
}
// 현재 트랜잭션 롤백 처리
rollback(status);
return;
}
// ...
} catch (RuntimeException ex) {
// 롤백처리가 필요한 예외인지 체크한다.
triggerRollbackIfNecessary(status, ex);
throw ex;
} catch (Error err) {
// 롤백처리가 필요한 에러인지 체크한다.
triggerRollbackIfNecessary(status, err);
throw err;
}
}- 동일한 클래스 내에서의 메서드 호출로 @Transactional이 작동하지 않는 문제
개발 중에는 클래스 내부의 메서드 호출을 피할 수 없습니다. 예를 들어 Test 클래스에 메서드 A가 있고, A가 다시 클래스 내부의 메서드 B를 호출하는 경우 (B 메서드가 public 또는 private로 선언되었는지 상관없이), A 메서드에 트랜잭션 주석을 선언하지 않았지만 B 메서드에는 선언되어 있습니다. 그러면 외부에서 메서드 A를 호출한 후에도 메서드 B의 트랜잭션이 작동하지 않습니다. 이것은 종종 발생하는 오류 중 하나입니다.
그렇다면 왜 이런 상황이 발생하는 것일까요? 실제로 이는 Spring AOP 프록시를 사용하면서 발생하는 문제입니다. Spring에서 생성한 프록시 객체가 관리하는 것은 현재 클래스 외부의 코드에서 트랜잭션 메서드가 호출될 때만 해당되기 때문입니다.
@Transactional
@GetMapping("/test")
private Integer A() throws Exception {
CityInfoDict cityInfoDict = new CityInfoDict();
cityInfoDict.setCityName("2");
/**
* B 메서드를 호출하여 3의 값을 가진 데이터를 삽입합니다.
/
this.insertB();
/*
* A 메서드에서 2의 값을 가진 데이터를 삽입합니다.
*/
int insert = cityInfoDictMapper.insert(cityInfoDict);
return insert;
}
@Transactional()
public Integer insertB() throws Exception {
CityInfoDict cityInfoDict = new CityInfoDict();
cityInfoDict.setCityName("3");
cityInfoDict.setParentCityId(3);
return cityInfoDictMapper.insert(cityInfoDict);
}
- 코드 중에 catch 가 있는 지 잘 살펴봐라. 어쩌면 이놈이 ‘먹어’ 버렸을수도..
@Transactional
private Integer A() throws Exception {
int insert = 0;
CityInfoDict cityInfoDict = new CityInfoDict();
cityInfoDict.setCityName("2");
cityInfoDict.setParentCityId(2);
try {
/**
* A 메서드 : 필드값이 2인 데이터 삽입
*/
insert = cityInfoDictMapper.insert(cityInfoDict);
/**
* B 메서드 : 필드값이 3인 데이터 삽입
*/
b.insertB();
} catch (Exception e) {
e.printStackTrace();
}
return insert;
}위 코드를 보면 아래와 같은 질문이 있을것 입니다.
질문: B 메스드 내부에서 exception 이 발생한다면, 이때 A메서드가 B 메서드를 catch 했다면, 이때 과연 정상적으로 transaction 이 rollback 될까요?
답은 : NO 입니다.
아래와 같이 예외발생!
org.springframework.transaction.UnexpectedRollbackException: Transaction rolled back because it has been marked as rollback-only정답은 A와 B 메서드 간에 트랜잭션 일관성을 유지하려면 메서드 B 내에서 발생한 예외를 처리하는 대신 throw하여 A 메서드 호출자가 처리하도록해야합니다.입니다.
코드를 수정해보았습니다.
@Transactional
private Integer A() throws Exception {
int insert = 0;
CityInfoDict cityInfoDict = new CityInfoDict();
cityInfoDict.setCityName("2");
cityInfoDict.setParentCityId(2);
try {
/**
* A 메서드: 2번 필드 삽입
*/
insert = cityInfoDictMapper.insert(cityInfoDict);
/**
* B 메서드: 3번 필드 삽입
*/
b.insertB();
} catch (Exception e) {
// 예외를 기록하고 처리하지 않습니다.
throw e;
}
return insert;
}이 수정된 코드에서는 B 메서드에서 예외가 발생하면 호출자인 A 메서드에게 전달되고, Spring 트랜잭션 매니저가 예외를 감지하여 트랜잭션을 롤백합니다.
마지막 케이스는 확률이 극히 낮습니다만…
- Database 엔진 자체가 트랜젝션을 지원하지 않을경우…
Mysql 를 예로 들면 …
기본적으로 Innodb 를 사용하지만 , 수동으로 myisam 을 사용하는 환경일경우 트랜젝션 자체를 지원하지않습니다. 이부분은 db 설정했던 당사자한테 가서 확인해보는편이 더빠를것 같네요.
오늘의 결론…
뭐 양날의 검이다 라고 앞에서 어급했듯이 단순 @Transactional 을 하더라도 왜 ? 그리고 여기에 위치했을때 과연 적절한지를 판단하고 작성하도록 하시다.
내저장소 바로가기 luxury515
'Back-end > 기타' 카테고리의 다른 글
| 시간 전역처리를 어노테이션 하나로 끝내자! (0) | 2023.04.17 |
|---|---|
| RequestBodyAdvice 와 ResponseBodyAdvice 사용법 (0) | 2023.04.17 |
| 유효성체크,예외처리,응답메시지에 대한 공통처리. (0) | 2023.04.17 |
| 필터(Filter) vs 인터셉터(Intercepter) (0) | 2023.04.17 |
| on duplicate key update (0) | 2023.04.16 |