Cargo는 Rust 언어의 패키지 관리자 및 빌드 도구입니다. 의존성 관리, 프로젝트 빌드, 테스트 실행 및 프로그램 배포 등을 도와줍니다. Rust 커뮤니티에서는 Cargo가 표준 빌드 도구로 자리 잡고 있으며, Rust 개발자에게 큰 편리함을 제공합니다.
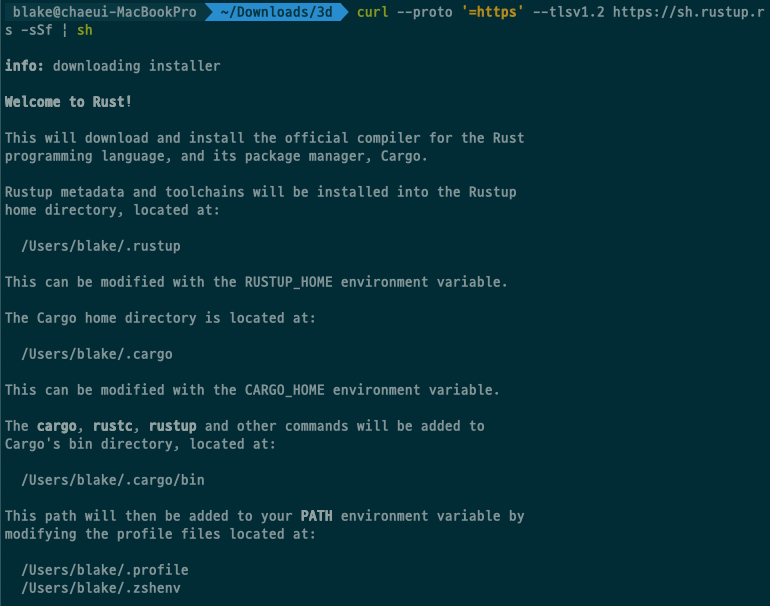
Cargo 설치 및 사용법 Rust를 설치할 때 Cargo가 함께 설치됩니다. Rust를 아직 설치하지 않았다면, Rust 입문부터 전문가까지 - Hello World! 시리즈의 첫 번째 편을 참고하거나 공식 웹사이트에서 다운로드하여 설치할 수 있습니다. 설치가 완료되면 다음 명령어를 사용하여 Cargo가 제대로 설치되었는지 확인할 수 있습니다:
cargo --version
# cargo 1.68.0 (115f34552 2023-02-26)위 명령어를 실행하면 Cargo의 버전이 출력되며, 이는 설치가 성공적으로 이루어졌음을 나타냅니다. 환경 검사가 완료되었으므로, 이제 Cargo를 배우기 시작할 차례입니다. 이전 글에서 사용한 명령어 중 하나는 "cargo new"입니다. 이 명령어는 첫 번째 Rust 프로젝트를 생성했습니다. 이전 글을 보지 않은 독자는 다음 명령어를 실행하여 프로젝트를 만들어 볼 수 있습니다.
cargo new hello_world위 명령어는 현재 디렉토리에 hello_world라는 새 프로젝트를 생성합니다. hello_world는 프로젝트 이름으로, 필요에 따라 수정할 수 있습니다. 프로젝트를 만든 후, hello_world 디렉토리를 엽니다. 디렉토리 구조는 다음과 같습니다.
/
├── Cargo.lock
├── Cargo.toml
├── crate-information.json
├── src/
│ ├── main.rs
└── target/
└── tools/Cargo가 생성한 가장 기본적인 프로젝트 구조로, src 디렉토리(개발 소스 코드 저장), Cargo.toml 파일(프로젝트 메타데이터, 컴파일 빌드, 제3자 라이브러리 종속성 관리 등)을 포함합니다. src 디렉토리에서 main.rs라는 파일을 볼 수 있으며, 이는 Rust 프로그램의 진입점으로 기본적인 main() 메서드를 구현합니다.
fn main() {
println!("Hello, world!");
}위의 코드는 main() 함수 안에 println!("Hello, world!"); 라는 매우 간단한 프로그램입니다. 이 프로그램은 명령 프롬프트 창에 "Hello, world!"라는 문장을 출력하는 기능을 합니다. VS Code에서 F5를 누르면 첫 번째 프로그램을 실행할 수 있습니다.
만약 VS Code 시작 구성을 구성하지 않았다면, 프로그램을 실행하기 전에 Cargo가 먼저 build 명령을 사용하여 프로젝트를 빌드하고 실행 가능한 파일을 생성합니다. 이제 cargo 명령어를 하나 더 배워보겠습니다.
cargo build이 명령은 프로젝트 루트 디렉토리에서 target 디렉토리를 생성하고, 그 안에 빌드 후 생성된 이진 파일이 포함됩니다. 기본적으로 Cargo는 hello_world라는 이름의 이진 파일을 생성합니다.
이진 파일을 생성하지 않고 프로젝트를 컴파일하고 싶을 때는 다음 명령어를 사용합니다.
cargo check이 명령은 코드가 컴파일될 수 있는지를 확인하지만, 이진 파일을 생성하지 않습니다.
빌드가 완료된 후 다음 명령어를 사용하여 프로그램을 실행할 수 있습니다.
cargo run이 명령은 프로젝트를 자동으로 빌드하고 실행합니다. 모든 것이 정상적으로 실행된다면, "Hello, world!"와 같은 출력을 볼 수 있을 것입니다.
자주 사용되는 Cargo 명령어들
이전 섹션에서는 Cargo의 new, build, run, check 네 가지 명령어를 사용했었는데, 이 외에도 Cargo는 다양한 명령어를 제공합니다. 그 중에서 가장 자주 사용되는 몇 가지 명령어를 소개하고 주석을 달아보겠습니다.
- new: 이 명령어는 새로운 Rust 프로젝트를 생성합니다. 프로젝트 이름과 타입(바이너리(bin) 또는 라이브러리(lib)) 두 개의 매개변수가 있으며, 기본적으로 이 명령어는 바이너리(bin) 프로젝트를 생성합니다.
- init: 이 명령어는 현재 디렉토리를 Rust 프로젝트로 초기화합니다. src 디렉토리와 Cargo.toml 파일이 생성됩니다.
- check: 이 명령어는 코드를 컴파일할 수 있는지 검사하지만, 바이너리 파일은 생성하지 않습니다.
- build: 이 명령어는 Rust 프로젝트를 컴파일하고 바이너리 파일을 생성합니다. 만약 프로젝트가 이미 컴파일되었다면, build 명령어는 컴파일 과정을 건너뛸 것입니다.
- run: 이 명령어는 Rust 프로젝트를 컴파일하고 실행합니다. 만약 프로젝트가 이미 컴파일되었다면, run 명령어는 컴파일 과정을 건너뛸 것입니다.
- test: 이 명령어는 프로젝트 내의 테스트를 실행합니다. 테스트 코드는 보통 src/test.rs나 src/lib.rs 파일에 작성됩니다.
- bench: 이 명령어는 프로젝트 내의 벤치마크 테스트를 실행합니다. 벤치마크 테스트는 코드의 성능을 테스트하기 위해 사용됩니다.
- doc: 이 명령어는 프로젝트 문서를 생성합니다. 보통 Rust 내장 문서 도구인 rustdoc을 사용하여 문서를 생성합니다.
- clean: 이 명령어는 프로젝트 빌드 파일과 생성된 바이너리 파일을 모두 삭제합니다.
- update: 이 명령어는 프로젝트 내의 의존성을 업데이트합니다.
- publish: 이 명령어는 프로젝트를 crates.io에 배포하여 다른 사람들이 사용할 수 있게 합니다.
더 많은 명령어는 cargo --help 또는 cargo <command> --help로 확인할 수 있습니다.
사용자 정의 확장 명령어
의존성 관리 Rust 프로젝트에서는 Cargo를 사용하여 의존성을 관리할 수 있습니다
이어서, 우리는 Cargo를 사용하여 종속성을 관리할 수 있습니다. Cargo.toml 파일을 편집하여 종속성을 추가할 수 있습니다.
예를 들어, 우리가 rand 라이브러리를 사용하여 난수를 생성하려고 한다면, 다음과 같은 내용을 Cargo.toml 파일에 추가할 수 있습니다:
[dependencies]
rand = "0.8.4"이 명령어는 Cargo에게 rand 라이브러리를 사용하려고 한다는 것을 알리며, 버전 0.8.4를 사용하고자 한다는 것을 지정합니다. 파일을 저장한 후, 다음 명령을 사용하여 종속성을 설치할 수 있습니다:
cargo build이 명령은 종속성을 자동으로 다운로드하고 설치합니다. 종속성을 사용할 때는, main.rs 파일에 다음과 같은 문장을 추가해야 합니다:
use rand::Rng;fn main() {
let mut rng = rand::thread_rng();
let n: u8 = rng.gen();
println!("Random number: {}", n);
}여기서 우리는 rand 라이브러리의 Rng 트레이트와 thread_rng 함수를 사용하여 난수를 생성합니다.
버전 관리
위의 예제에서는 0.8.4 버전의 rand 라이브러리 의존성을 지정하고, 명령 프롬프트에서 무작위 숫자를 출력했습니다. 이번에는 의존성 관리를 더 자세히 배워봅시다.
특정 버전을 지정하는 것 외에도, 논리 연산자를 사용하여 버전 범위를 제어할 수 있습니다. 아래는 구체적인 예시입니다.
=: 특정 버전과 동일합니다. 버전 번호를 직접 입력하는 것과 같습니다.
: 특정 버전보다 높은 버전입니다. <=: 특정 버전보다 작거나 같은 버전입니다. ~: 특정 버전과 비슷합니다. 예를 들어, 1.2.3은 대략 1.2.3과 같으며, 마지막 숫자가 다른 경우에도 허용됩니다. 예를 들어, 1.2.4입니다. ^: 특정 버전과 호환됩니다. 예를 들어, ^1.2.3은 1.2.x 시리즈의 모든 버전과 호환되지만 2.0.0 이상 버전과는 호환되지 않습니다.
예를 들어, 0.7.3 이상 0.8.4 미만 버전의 라이브러리 의존성을 지정하려면 다음과 같이 작성할 수 있습니다.
[dependencies]
rand = ">=0.7.3, <0.8.4"
의존성 항목의 기능 지정
일부 라이브러리는 여러 기능을 제공하여 일부 기능을 활성화하거나 비활성화 할 수 있습니다. 예를 들어, serde 라이브러리는 파생 매크로를 활성화하는 derive 기능을 제공합니다. 의존성 항목의 기능을 지정하려면 다음 구문을 사용할 수 있습니다.
[dependencies]
라이브러리_이름 = { version = "버전", features = ["기능_이름"] }log는 로그 기록을 위한 라이브러리입니다. 다음은 몇 가지 일반적인 기능과 사용 예시입니다.
- std: log의 표준 라이브러리 지원을 활성화하여 표준 라이브러리 환경에서 log를 사용할 수 있습니다.
- env_logger: log의 환경 변수 지원을 활성화하여 환경 변수를 사용하여 로그 출력을 제어할 수 있습니다.
- log4rs: log4rs 지원을 활성화하여 log4rs 라이브러리를 사용하여 로그 출력을 구성할 수 있습니다.
- simplelog: simplelog 지원을 활성화합니다. simplelog 라이브러리를 사용하여 로그 출력을 구성할 수 있습니다.
다음은 예제입니다: [dependencies] log = { version = "0.4", features = ["std"] }
[dependencies]
log = { version = "0.4", features = ["std"] }[dependencies]
log = { version = "0.4", default-features = false }일부 경우에는 로컬 파일 시스템에 있는 라이브러리를 사용해야 할 수 있습니다. 이를 위해 의존성 경로를 지정할 수 있습니다:
[dependencies]
rand = { path = "../rand" }이 예제에서는 "../rand" 경로의 "rand" 라이브러리를 지정하고 있습니다. 이는 Cargo 컴파일러에게 우리의 프로젝트가 로컬 파일 시스템에 있는 "rand" 라이브러리를 필요로 함을 알려줍니다. "cargo build" 명령을 실행하면, Cargo는 자동으로 지정된 경로의 "rand" 라이브러리를 컴파일하고 프로젝트에 추가합니다.
로컬 파일 시스템에서 라이브러리를 사용하는 것 외에도, git 저장소에서 라이브러리를 사용할 수 있습니다. 의존성 git 저장소를 지정하려면 다음 구문을 사용할 수 있습니다:
[dependencies]
rand = { git = "https://github.com/rust-lang-nursery/rand.git" }
메타데이터
이전 섹션에서는 Cargo의 품질 관리 및 의존성 관리 기능을 설명했습니다. 이번 섹션에서는 Cargo.toml 파일에서 정의된 프로그램 메타데이터 (예 : 프로그램 이름, 버전, 작성자, 설명 등)를 설명합니다.
makefileCopy code
[package]
## 프로젝트 이름
name = "hello_world"
## 버전
version = "0.1.0"
## 작성자, 여러 명일 경우 쉼표로 구분
authors = ["Your Name <your_email@example.com>"]
## 프로젝트 설명
description = "A hello world program in Rust."
## Rust 언어 버전, 현재 2015, 2018 및 2021 세 가지 버전을 지원합니다.
edition = "2021"
기본 메타데이터 이외에도, [package.metadata] 아래에서 전용 메타데이터를 사용자 정의할 수 있습니다.
makefileCopy code
[package.metadata]
url = "https://github.com/username/hello-world"
doc = "https://docs.rs/hello-world"
repository = "https://github.com/username/hello-world.git"
결론
이를 통해 Rust 언어의 패키지 관리자 및 빌드 도구인 Cargo를 사용하여 새로운 Rust 프로젝트를 만들고, Rust 프로그램을 작성하고, 프로그램을 빌드하고 실행하며, 의존성을 추가하는 방법을 배웠습니다.
내저장소 바로가기 luxury515
'Back-end > Rust' 카테고리의 다른 글
| Rust 아는 척 해보기-3 직렬화 와 역직렬화 (0) | 2023.04.16 |
|---|---|
| Rust 아는 척 해보기-1 설치 및 개발환경세팅 (0) | 2023.04.16 |